
Hermes上线MoA功能!比Opus 4.8和GPT-5.5还猛
Hermes上线MoA功能!比Opus 4.8和GPT-5.5还猛近日,Hermes Agent上线了MoA(Mixture of Agents)功能,支持用户自由组合多种模型作为虚拟模型使用,在Nous Research即将发布的基准测试中,这个混合模型的评分超过了Opus 4.8 和GPT-5.5。
来自主题: AI资讯
9561 点击 2026-07-01 00:22
 搜索
搜索
近日,Hermes Agent上线了MoA(Mixture of Agents)功能,支持用户自由组合多种模型作为虚拟模型使用,在Nous Research即将发布的基准测试中,这个混合模型的评分超过了Opus 4.8 和GPT-5.5。

Mindverse 完成由美团领投的 A 轮融资,元禾璞华、韶音、变量资本和老股东追加跟投。Mindverse (心洲科技) 是少数把赌注押在模型「内部」的一家创企,它在通用大模型的基础上,用强化学习让它从复杂、多步骤的真实任务中学会如何把事做成,让模型从「知道很多」变为「能办好事」。

过去十年,大模型世界里很多最关键的技术路线背后,都能看到Andrew Dai的身影。从早期预训练与监督微调,到后来主流的MoE(Mixture of Experts)架构;从Google Brain最初只有几十人的研究时代,到后来支撑Gemini的大规模数据体系,这位在 Google 工作超过14年的研究科学家,几乎站在了大模型时代每一次关键转折的现场。
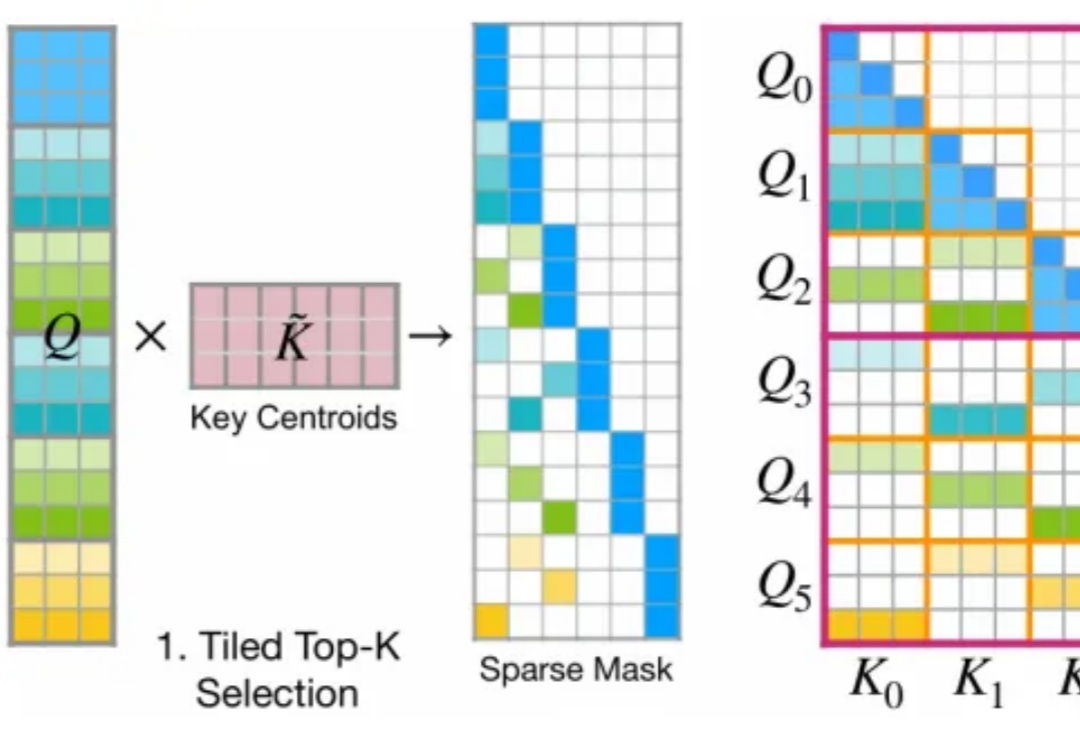
今年 2 月,月之暗面提出了一种名为 MoBA 的注意力机制,即 Mixture of Block Attention,可以直译为「块注意力混合」。

要问最近哪个模型最火,混合专家模型(MoE,Mixture of Experts)绝对是榜上提名的那一个。
2 月 18 日,月之暗面发布了一篇关于稀疏注意力框架 MoBA 的论文。MoBA 框架借鉴了 Mixture of Experts(MoE)的理念,提升了处理长文本的效率,它的上下文长度可扩展至 10M。并且,MoBA 支持在全注意力和稀疏注意力之间无缝切换,使得与现有的预训练模型兼容性大幅提升。

时序大模型,参数规模突破十亿级别。 来自全球多只华人研究团队提出了一种基于混合专家架构(Mixture of Experts, MoE)的时间序列基础模型——Time-MoE。